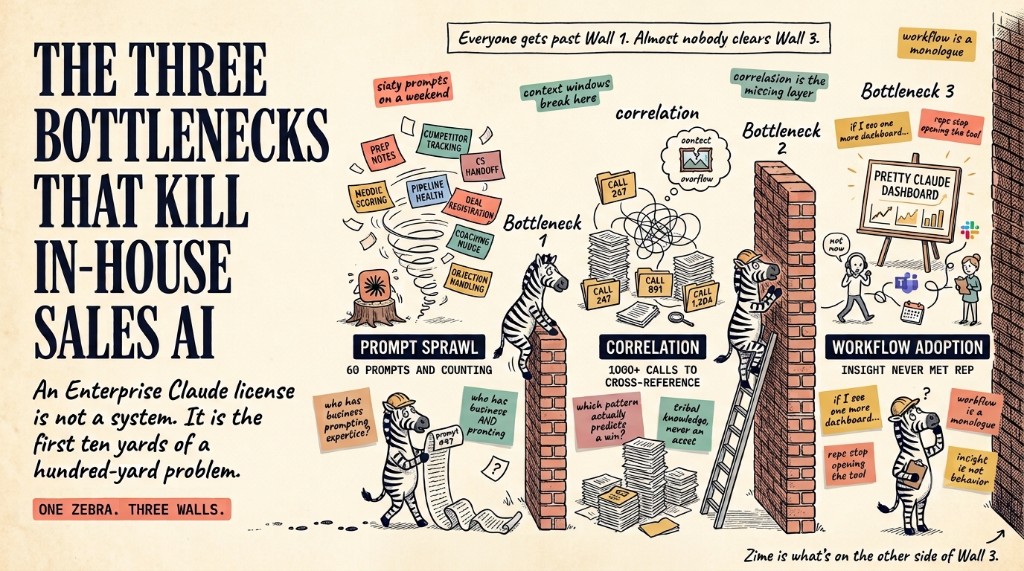
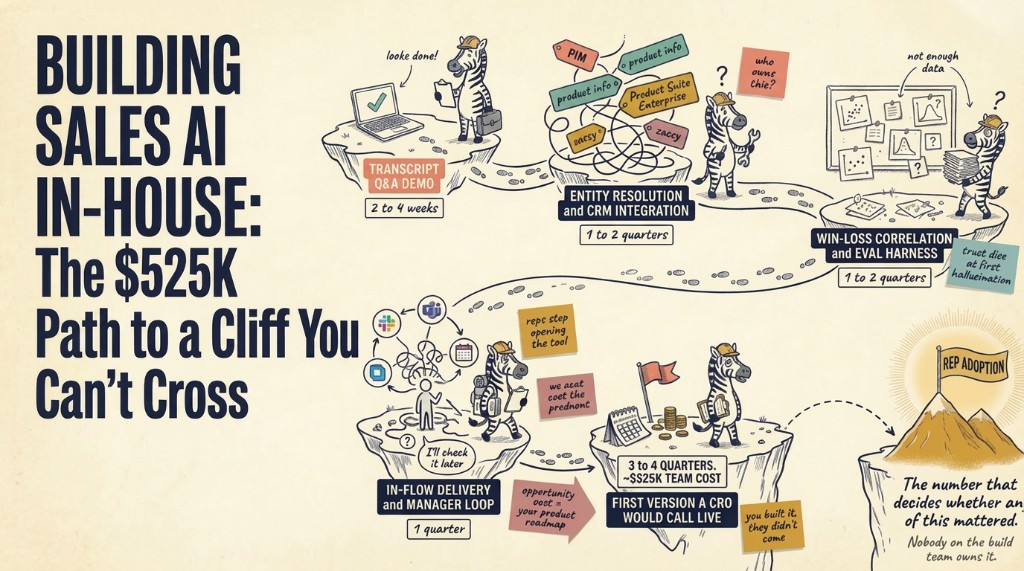
Enforcing MEDDIC on live calls is not a training problem. It is a behavioral infrastructure problem. Most revenue teams that ask this question already have the framework, the playbooks, and the certifications. What they are missing is the operational layer that makes MEDDIC behavior visible in the moment a rep is actually on a call with a prospect.
The direct answer: you enforce MEDDIC on live calls by creating a pre-to-post-call feedback loop that surfaces qualification gaps specific to each deal, scores rep behavior against your own discovery criteria after every call, and makes those gaps actionable for managers in pipeline reviews. Without that infrastructure, MEDDIC stays a concept that lives in training decks and gets forgotten the moment a rep joins a live discovery call.
Who This Is Really About
This challenge sits squarely with VP Sales, CROs, and Revenue Enablement leaders at B2B SaaS companies that have scaled past 30 reps and are running multi-product or multi-segment motions.
The pattern is consistent: the company has invested in MEDDIC or MEDDICC, built out playbooks in Highspot or Notion, put reps through certification sessions, and still sees wildly inconsistent discovery execution. Some reps nail consequence of inaction and decision criteria. Most do not. Deals pile up in the pipeline that look qualified in the CRM but have no timeline confirmed, no economic buyer engaged, and no cost of inaction documented.
If your managers are spending pipeline reviews asking "Is this deal real?" instead of "Which MEDDIC behaviors are missing and who owns closing those gaps?", this article is for you.
The Real Problem
The challenge is not that reps cannot explain MEDDIC. The problem is that knowing a qualification framework and applying it under pressure in a live conversation are two entirely different cognitive tasks.
At the rep level, the symptoms are inconsistency. Discovery calls where "Identify Pain" happens but "Decision Criteria" and "Metrics" are skipped. Deals that are manually marked qualified in the CRM without a confirmed economic buyer or a stated timeline. At the manager level, it looks like reactive coaching: reviewing deals only when they stall, trying to reconstruct what happened in a call from notes a rep wrote two days later.
At the leadership level, it becomes a forecast problem. According to research cited by Gartner, 77% of sellers struggle to complete tasks efficiently due to poorly integrated frameworks that add complexity instead of clarifying it. The qualification framework becomes another administrative layer reps route around, and leaders lose visibility into what is actually happening on calls.
What Is Actually Causing This
1. MEDDIC Lives in Training, Not in the Workflow
Most teams treat MEDDIC as a knowledge problem and solve it with training events. But Gartner identifies behavioral nudges and just-in-time learning as the actual drivers of in-call behavior change, not sessions that happen quarterly in a conference room. When there is no mechanism that delivers MEDDIC criteria to the rep in the context of the specific deal they are about to discuss, the training decays within weeks of the workshop.
2. Playbooks Are Academic, Not Situational
Playbooks document what good discovery looks like in the abstract. They do not account for the fact that a large enterprise deal with a 12 to 36 month hardware migration cycle requires a completely different "Identify Pain" approach than a mid-market SaaS expansion conversation. The nuances that separate a 10% win rate rep from a 25% win rate rep are rarely captured in documentation, and even when they are, no rep is opening Highspot to read a playbook 10 minutes before a call. Forrester notes that 89% of sales enablement teams launch new methodologies annually, creating change fatigue in reps who face shifting priorities without contextual support.
3. CRM Compliance Is Not MEDDIC Execution
Teams routinely confuse field completion with sales methodology enforcement. A rep can fill in every MEDDIC field after a call without having executed a single qualification behavior during it. A manager sees green dashboards. The forecast looks healthy. The behaviors that actually move deals forward remain invisible.
4. Only the Top 10% Execute Naturally
Across revenue teams, the same pattern holds: roughly 10% of reps will follow a qualification methodology with fidelity regardless of reinforcement. The other 90% need something more than a playbook link and a manager telling them to "run MEDDIC harder." Organizations that truly operationalize MEDDIC see quota attainment rates rise from around 55% to over 75% within two years, but those results are only possible with sustained behavioral reinforcement, not one-time certification.
What Sales Teams Usually Try First
The instinctive response to MEDDIC non-adoption is more training. Teams run updated certification programs, rebuild playbooks with sharper templates, and roll out conversation intelligence tools like Gong or Clary expecting that call recording and generic AI scoring will surface where MEDDIC is missing.
Others invest in CRM governance: mandatory MEDDIC fields, pipeline review rituals focused on field completion, and manager-enforced deal inspections. Some organizations spend months trying to fine-tune their existing call recording tools to score against their custom qualification criteria, often finding that the platform was built for generic insights, not nuanced company-specific discovery execution. These are all logical responses. They reflect the right instincts about the problem.
Why These Approaches Fail
Training creates knowledge, not behavior. The moment a rep is live on a call and the prospect takes the conversation in an unexpected direction, the certification fades. Real behavior change requires the right information at the right moment, not a slide deck from last quarter.
Generic conversation intelligence tools capture what happened on a call. They do not understand what should have happened based on your deal stage, your ICP, and your specific discovery criteria. A platform can tell you a rep mentioned "pricing" but cannot tell you whether the rep successfully established the economic buyer's evaluation criteria or uncovered a compelling reason for the customer to move. That gap is the difference between activity visibility and behavioral enforcement.
CRM mandates create compliance theater. Reps mark fields complete because they are required to, not because the underlying qualification behaviors occurred. Companies have reported spending years attempting to configure existing tools for nuanced discovery scoring with limited results. The fine-tuning required to make a general-purpose AI understand company-specific sales nuances, such as how a specific rep should articulate the cost of staying on legacy infrastructure versus migrating to a cloud-native platform, is significant, and most teams neither have the time nor the engineering resources to sustain it.
What Actually Drives Behavior Change
The revenue teams that successfully enforce MEDDIC on live calls operate differently in three ways.
First, they make the playbook situational, not static. Instead of one discovery guide, they build deal-stage-specific criteria: what "Identify Pain" looks like in an early-stage qualification call versus a late-stage evaluation, what questions surface the economic buyer in enterprise versus mid-market. The playbook is versioned by context, not written as a universal script.
Second, they close the pre-call to post-call loop. Before each call, reps receive a brief that surfaces MEDDIC gaps from the prior interaction: which criteria were not addressed, what objections remain open, how top performers handled a similar situation. Post-call, behavior is scored automatically against the company-specific qualification criteria, not generic industry benchmarks.
Third, managers shift from outcome inspection to behavior inspection. Instead of reviewing whether a deal is in the right CRM stage, managers inspect whether the MEDDIC behaviors for that stage were executed. Coaching becomes specific. "Consequence of inaction was mentioned but not anchored to a timeline" is actionable. "The deal feels soft" is not.
What Sales Leaders Are Actually Saying
Revenue and enablement leaders who have confronted this problem describe it with a precision that generic training assessments rarely capture.
Navin Madhavan leads Revenue Operations at Amagi, a B2B SaaS company in the streaming and broadcast technology space, operating globally with a growing enterprise and mid-market sales team split across two distinct product lines. When describing the operational state of their sales execution:
"Playbooks are really not credible, or updated. It's in an embarrassing state, and driving adoption of playbooks is a challenge. Trainings are not working. We're losing revenue here."
Christan is a Sales Enablement Leader at a US-based cybersecurity SaaS company that sells DevOps security products and serves enterprise and mid-market customers through a direct sales motion. Her team had recently run an enablement push around a timely product narrative tied to real-world security incidents. When asked whether the sessions had actually translated into rep behavior on calls:
"But are these discussions happening? Did they take away anything from that enablement session? I don't know. I don't even know what calls they go and listen to."
A Practical Framework to Enforce MEDDIC on Live Calls
Step 1: Map MEDDIC Criteria to Deal Stages and Segments
Define what each MEDDIC component looks like at each specific stage for each segment. What does "Decision Process" look like in a first discovery call for enterprise versus mid-market? This transforms MEDDIC from a generic checklist into executable, stage-specific behavior criteria that reps and managers can inspect against.
Step 2: Build Company-Specific Qualification Intelligence
Analyze your top rep calls to understand how winning discovery actually sounds in your market. What questions surface the economic buyer in your product category? How do your best reps establish consequence of inaction for a customer who has no pressing reason to move? This data becomes the foundation of a qualification playbook that is credible to reps because it is derived from real winning calls, not theoretical best practices. Companies that have built discovery playbooks this way have seen their "consequence of inaction" execution rate on calls double from 40% to over 80%, with early-stage win rates improving from 10% to 18% as a direct result.
Step 3: Deliver Situational Pre-Call Prep
Before each call, reps should receive a brief that surfaces the specific MEDDIC gaps from their last interaction with that account. Which criteria were not addressed? What objections did the prospect raise that went unanswered? What would a top rep do next in this situation? This shifts the playbook from a document that lives in a drive to a preparation tool that shows up in Slack or Teams 60 minutes before the call.
Step 4: Score Post-Call Behavior Against Your Criteria Automatically
After every call, qualification behavior should be scored against your MEDDIC criteria, not self-reported by the rep. The score should reflect whether the rep executed the behaviors, not whether the CRM fields were filled in. Gartner research shows that 58% of reps need dedicated coaching sessions just to function effectively on calls, and that behavioral reinforcement loops are what drive durable performance improvement. A behavioral score creates the data managers need to coach on specifics.
Step 5: Make MEDDIC Gaps Visible in Pipeline Reviews
Give managers a deal inspection view that shows MEDDIC completeness by deal, by rep, and by stage. In a pipeline of 379 deals, identifying that 69 are marked qualified with no confirmed timeline or consequence of inaction is the difference between accurate forecasting and pipeline inflation. This single shift makes coaching specific and makes qualification accountable to outcomes, not optics.
If You Are Facing This Problem
Ask these questions before assuming the problem is the framework:
- Do your managers inspect MEDDIC behaviors at the call level, or only review CRM field completion?
- Can you identify which specific MEDDIC criteria are most commonly missing in deals that stall or lose?
- Are reps receiving any pre-call guidance that reflects MEDDIC gaps from their last interaction with that account?
- Does your conversation intelligence tool score calls against your company-specific qualification nuances, or against generic industry best practices?
- When a rep marks a deal as "qualified" in your CRM, can anyone verify whether the underlying discovery conversation actually happened?
- Do your playbooks differentiate by deal stage, segment, and competitive scenario, or are they written as a single universal guide?
- Are win-loss patterns being fed back into your qualification criteria, or does the playbook stay static after initial rollout?
Conclusion
Enforcing MEDDIC on live calls requires building the infrastructure that connects methodology to in-call behavior. Training creates awareness. Playbooks create documentation. Neither creates execution. The gap between knowing MEDDIC and running MEDDIC in a live discovery call is where most revenue teams lose pipeline quality, forecast accuracy, and win rate potential.
Companies that have adopted MEDDIC with genuine behavioral reinforcement report 20 to 30% higher close rates compared to teams using traditional qualification approaches. The difference is never the framework. It is always the feedback loop, the situational playbook, and the visibility layer that makes MEDDIC a live call behavior rather than a post-call checklist.
Take the Next Step
If MEDDIC enforcement is a live execution gap at your organization, seeing how other teams have operationalized this across the pre-call, post-call, and manager coaching layers is often more useful than reading another framework guide.
Zime is built to make qualification behavior observable and coachable at scale. It builds a discovery brain from your top rep calls and product content, applies it automatically against every deal, and gives managers the deal-level view to coach on behavior, not just outcomes. You can explore how this works through a short working session built around your own deal scenarios, not a generic product walkthrough.
Book a Demo with Zime