What is an entity in sales AI?
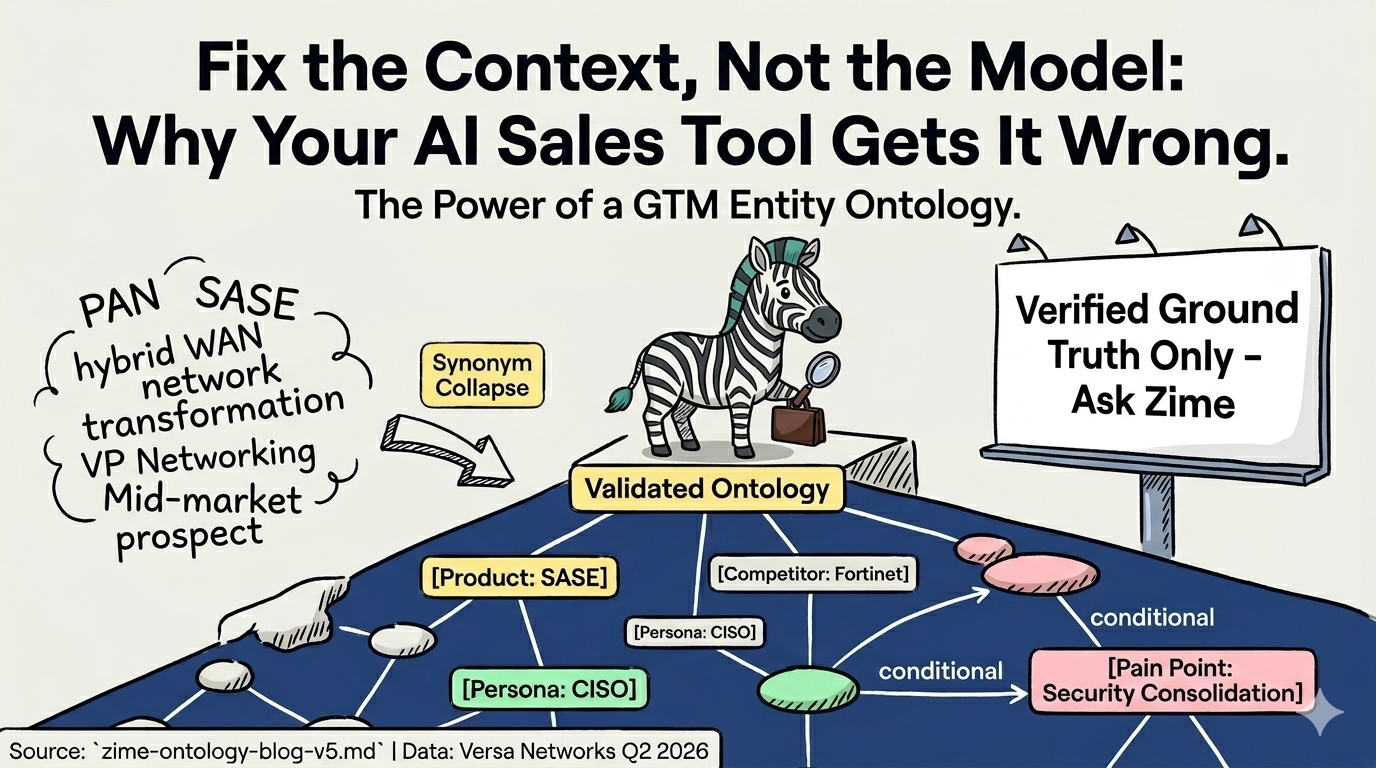
An entity is any named thing that your GTM team sells around, talks about, and needs to know. Products, competitors, pain points, objections, personas, industries you sell into, regions with different pricing or buying behavior, and deal stages in your CRM are all entities.
These aren't just taxonomy. They're the ontology, the structured vocabulary that every downstream AI decision depends on.
Versa is a good illustration of why this matters. In their sales motion, SD-WAN, SSE, and SASE are not synonyms and they are not interchangeable. As one of their reps put it: networking buyers get led with SD-WAN, security buyers get led with SSE, and SASE is the combined story. In large enterprises, networking and security often sit in separate buying centers, so the same account may need two entirely different pitches depending on who picks up the phone.
A generic AI that treats SD-WAN, SSE, and SASE as interchangeable keywords will produce the wrong prep, the wrong coaching, and the wrong summary, every time. Not because the model is weak. Because nobody told it which word means what, to whom, in which deal.
When a rep asks "what should I say about security consolidation to this CISO at a mid-market healthcare company?", the AI needs to already know:
Pain point"Security consolidation" is a pain point, not a feature.
PersonaThe CISO persona buys differently than the VP of Networking.
SegmentMid-market healthcare is a segment with specific buying triggers.
MappingWhich of your products maps to which pain point, and what the win looks like.
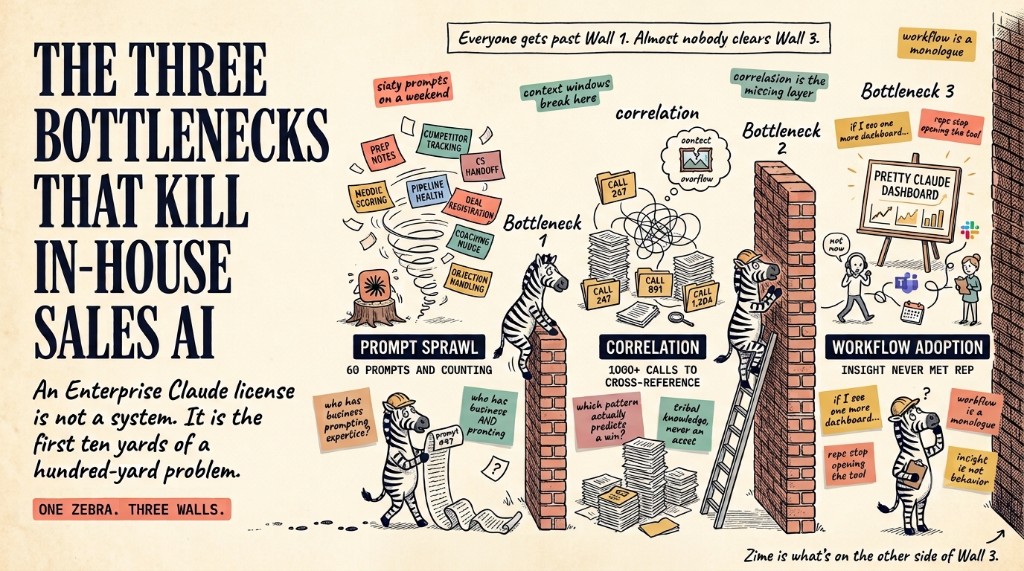
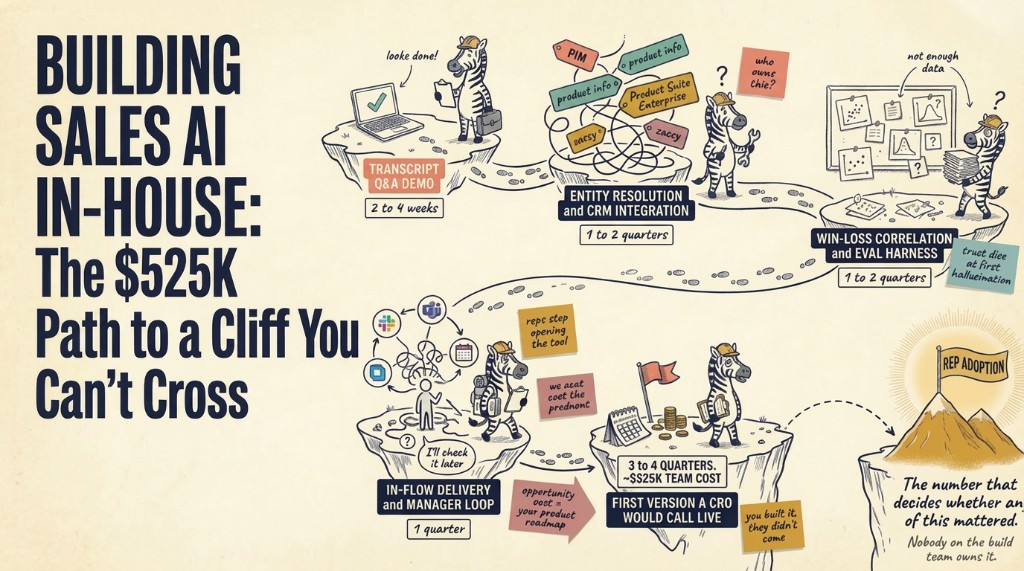
Without that clean entity list, the AI guesses. It pulls generic patterns from generic data. It gives you a confident-sounding answer that would fail on any real call.
That's not a model quality problem. GPT-4, Claude, Gemini, any of them will hallucinate in this gap. The fix isn't a smarter model. It's better ground truth.